0. Why need special_read/write ?
- 这里的 special_read 是对 vnode 的统一抽象接口而言
eg: read() / write() / mkdir() / link() / … - vnode 的类型(vn_mode)如下:
- S_IFDIR directory
- S_IFREG regular
- S_IFLNK symlink
- S_IFCHR character special
- S_IFBLK block special
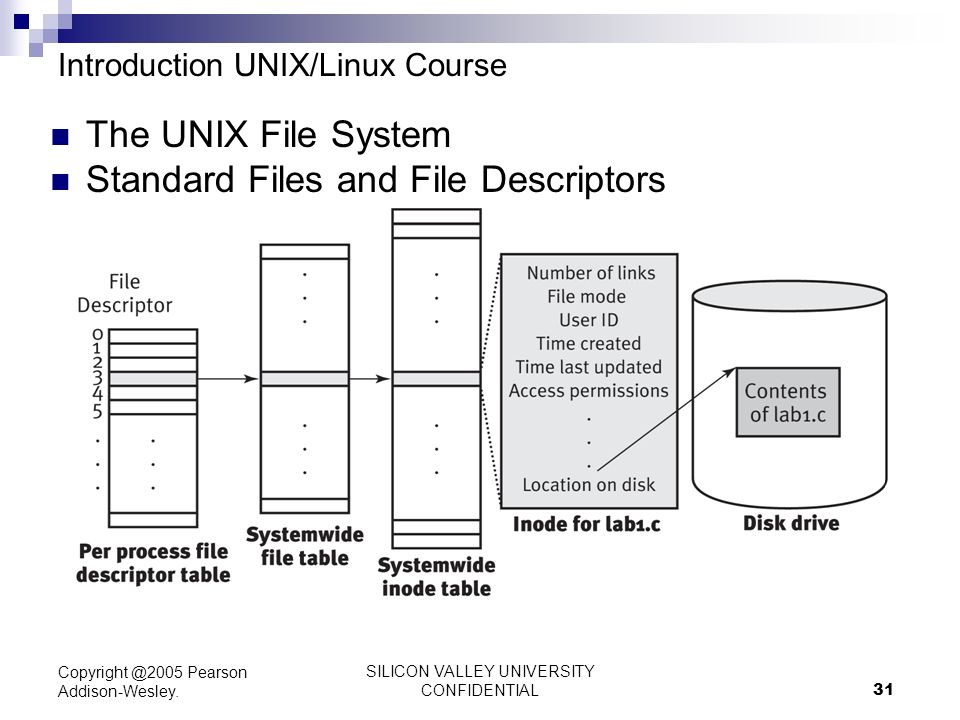
- File System 使用 vnode 来抽象除了内存(memory)之外所有的设备,包括:硬盘、屏幕、键盘
- 因此在 File System 的世界,所有外设都由 vnode 统一映射
- 区别在于: vnode 的成员变量 vn_mode 指定外设类型
- 特殊的外设,vn_devid/vn_cdev/vn_bdev 记录了相关信息
- 尽管不同的文件系统对不同类型的 vnode 统一管理,如:file vnode/directory vnode/char vnode/ block vnode;但是后两个特殊的 vnode 类型(char/block) 却不受文件系统的影响
- 因为char/block 两类实际上相当于 IO 设备vnode节点,独立于文件系统;只不过为了接口统一,操作系统将 IO 设备的操作集成到 FS 文件系统中了。
- 因此,对于char/block特设vnode 的抽象接口,应该交由相应的 IO设备去实现,而不应该在下放给 specific FS 去实现。这也是为什么在 vnode.c 这里要实现 special_read() | special_write()的原因
1. special file read
1 | int special_file_read(vnode_t *file, off_t offset, |
- 读取vnode的vn_mode,判断 file vnode 的类型
- if S_ISBLK(file->vn_mode),return -ENOTSUP;
- if S_ISCHR(file->vn_mode),检查是否含有相关函数
- 交由 special file (char device) 去实现读操作
- file->vn_cdev->cd_ops->read(file->vn_cdev, offset, buf, count);
2. special file write
1 | int special_file_write(vnode_t *file, off_t offset, |
- 读取vnode的vn_mode,判断 file vnode 的类型
- if S_ISBLK(file->vn_mode),return -ENOTSUP;
- if S_ISCHR(file->vn_mode),检查是否含有相关函数
- 交由 special file (char device) 去实现写操作
- file->vn_cdev->cd_ops->write(file->vn_cdev, offset, buf, count);